The HPE Cray Programming Environment¶
Every user needs to know the basics about the programming environment as after all most software is installed through the programming environment, and to some extent it also determines how programs should be run.
Why do I need to know this?¶

The typical reaction of someone who only wants to run software on an HPC system when confronted with a talk about development tools is "I only want to run some programs, why do I need to know about programming environments?"
The answer is that development environments are an intrinsic part of an HPC system. No HPC system is as polished as a personal computer and the software users want to use is typically very unpolished.
Programs on an HPC cluster are preferably installed from sources to generate binaries optimised for the system. CPUs have gotten new instructions over time that can sometimes speed-up execution of a program a lot, and compiler optimisations that take specific strengths and weaknesses of particular CPUs into account can also gain some performance. Even just a 10% performance gain on an investment of 160 million EURO such as LUMI means a lot of money. When running, the build environment on most systems needs to be at least partially recreated. This is somewhat less relevant on Cray systems as we will see at the end of this part of the course, but if you want reproducibility it becomes important again.
Even when installing software from prebuild binaries some modules might still be needed, e.g., as you may want to inject an optimised MPI library as we shall see in the container section of this course.
The operating system on LUMI¶

The login nodes of LUMI run a regular SUSE Linux Enterprise Server 15 SP4 distribution. The compute nodes however run Cray OS, a restricted version of the SUSE Linux that runs on the login nodes. Some daemons are inactive or configured differently and Cray also does not support all regular file systems. The goal of this is to minimize OS jitter, interrupts that the OS handles and slow down random cores at random moments, that can limit scalability of programs. Yet on the GPU nodes there was still the need to reserve one core for the OS and driver processes.
This also implies that some software that works perfectly fine on the login nodes may not
work on the compute nodes. E.g., there is no /run/user/$UID directory and we have experienced
that D-Bus (which stands for Desktop-Bus) also does not work as one should expect.
Large HPC clusters also have a small system image, so don't expect all the bells-and-whistles from a Linux workstation to be present on a large supercomputer. Since LUMI compute nodes are diskless, the system image actually occupies RAM which is another reason to keep it small.
Programming models¶

On LUMI we have several C/C++ and Fortran compilers. These will be discussed more in this session.
There is also support for MPI and SHMEM for distributed applications. And we also support RCCL, the ROCm-equivalent of the CUDA NCCL library that is popular in machine learning packages.
All compilers have some level of OpenMP support, and two compilers support OpenMP offload to the AMD GPUs, but again more about that later.
OpenACC, the other directive-based model for GPU offloading, is only supported in the Cray Fortran compiler. There is no commitment of neither HPE Cray or AMD to extend that support to C/C++ or other compilers, even though there is work going on in the LLVM community and several compilers on the system are based on LLVM.
The other important programming model for AMD GPUs is HIP, which is their alternative for the proprietary CUDA model. It does not support all CUDA features though (basically it is more CUDA 7 or 8 level) and there is also no equivalent to CUDA Fortran.
The commitment to OpenCL is very unclear, and this actually holds for other GPU vendors also.
We also try to provide SYCL as it is a programming language/model that works on all three GPU families currently used in HPC.
Python is of course pre-installed on the system but we do ask to use big Python installations in a special way as Python puts a tremendous load on the file system. More about that later in this course.
Some users also report some success in running Julia. We don't have full support though and have to depend on binaries as provided by julialang.org. The AMD GPUs are not yet fully supported by Julia.
It is important to realise that there is no CUDA on AMD GPUs and there will never be as this is a proprietary technology that other vendors cannot implement. LUMI will in the future have some nodes with NVIDIA GPUs but these nodes are meant for visualisation and not for compute.
The development environment on LUMI¶

Long ago, Cray designed its own processors and hence had to develop their own compilers. They kept doing so, also when they moved to using more standard components, and had a lot of expertise in that field, especially when it comes to the needs of scientific codes, programming models that are almost only used in scientific computing or stem from such projects, and as they develop their own interconnects, it does make sense to also develop an MPI implementation that can use the interconnect in an optimal way. They also have a long tradition in developing performance measurement and analysis tools and debugging tools that work in the context of HPC.
The first important component of the HPE Cray Programming Environment is the compilers. Cray still builds its own compilers for C/C++ and Fortran, called the Cray Compiling Environment (CCE). Furthermore, the GNU compilers are also supported on every Cray system, though at the moment AMD GPU support is not enabled. Depending on the hardware of the system other compilers will also be provided and integrated in the environment. On LUMI two other compilers are available: the AMD AOCC compiler for CPU-only code and the AMD ROCm compilers for GPU programming. Both contain a C/C++ compiler based on Clang and LLVM and a Fortran compiler which is currently based on the former PGI frontend with LLVM backend. The ROCm compilers also contain the support for HIP, AMD's CUDA clone.
The second component is the Cray Scientific and Math libraries, containing the usual suspects as BLAS, LAPACK and ScaLAPACK, and FFTW, but also some data libraries and Cray-only libraries.
The third component is the Cray Message Passing Toolkit. It provides an MPI implementation optimized for Cray systems, but also the Cray SHMEM libraries, an implementation of OpenSHMEM 1.5.
The fourth component is some Cray-unique sauce to integrate all these components, and support for hugepages to make memory access more efficient for some programs that allocate huge chunks of memory at once.
Other components include the Cray Performance Measurement and Analysis Tools and the Cray Debugging Support Tools that will not be discussed in this one-day course, and Python and R modules that both also provide some packages compiled with support for the Cray Scientific Libraries.
Besides the tools provided by HPE Cray, several of the development tools from the ROCm stack are also available on the system while some others can be user-installed (and one of those, Omniperf, is not available due to security concerns). Furthermore there are some third party tools available on LUMI, including Linaro Forge (previously ARM Forge) and Vampir and some open source profiling tools.
We will now discuss some of these components in a little bit more detail, but refer to the 4-day trainings that we organise three times a year with HPE for more material.
The Cray Compiling Environment¶

The Cray Compiling Environment are the default compilers on many Cray systems and on LUMI. These compilers are designed specifically for scientific software in an HPC environment. The current versions use are LLVM-based with extensions by HPE Cray for automatic vectorization and shared memory parallelization, technology that they have experience with since the late '70s or '80s.
The compiler offers extensive standards support. The C and C++ compiler is essentially their own build of Clang with LLVM with some of their optimisation plugins and OpenMP run-time. The version numbering of the CCE currently follows the major versions of the Clang compiler used. The support for C and C++ language standards corresponds to that of Clang. The Fortran compiler uses a frontend developed by HPE Cray, but an LLVM-based backend. The compiler supports most of Fortran 2018 (ISO/IEC 1539:2018). The CCE Fortran compiler is known to be very strict with language standards. Programs that use GNU or Intel extensions will usually fail to compile, and unfortunately since many developers only test with these compilers, much Fortran code is not fully standards compliant and will fail.
All CCE compilers support OpenMP, with offload for AMD and NVIDIA GPUs. They claim full OpenMP 4.5 support with partial (and growing) support for OpenMP 5.0 and 5.1. More information about the OpenMP support is found by checking a manual page:
man intro_openmp
cce module is loaded.
The Fortran compiler also supports OpenACC for AMD and NVIDIA GPUs. That implementation
claims to be fully OpenACC 2.0 compliant, and offers partial support for OpenACC 2.x/3.x.
Information is available via
man intro_openacc
The CCE compilers also offer support for some PGAS (Partitioned Global Address Space) languages. UPC 1.2 is supported, as is Fortran 2008 coarray support. These implementations do not require a preprocessor that first translates the code to regular C or Fortran. There is also support for debugging with Linaro Forge.
Lastly, there are also bindings for MPI.
Scientific and math libraries¶

Some mathematical libraries have become so popular that they basically define an API for which several implementations exist, and CPU manufacturers and some open source groups spend a significant amount of resources to make optimal implementations for each CPU architecture.
The most notorious library of that type is BLAS, a set of basic linear algebra subroutines for vector-vector, matrix-vector and matrix-matrix implementations. It is the basis for many other libraries that need those linear algebra operations, including Lapack, a library with solvers for linear systems and eigenvalue problems.
The HPE Cray LibSci library contains BLAS and its C-interface CBLAS, and LAPACK and its C interface LAPACKE. It also adds ScaLAPACK, a distributed memory version of LAPACK, and BLACS, the Basic Linear Algebra Communication Subprograms, which is the communication layer used by ScaLAPACK. The BLAS library combines implementations from different sources, to try to offer the most optimal one for several architectures and a range of matrix and vector sizes.
LibSci also contains one component which is HPE Cray-only: IRT, the Iterative Refinement Toolkit, which allows to do mixed precision computations for LAPACK operations that can speed up the generation of a double precision result with nearly a factor of two for those problems that are suited for iterative refinement. If you are familiar with numerical analysis, you probably know that the matrix should not be too ill-conditioned for that.
There is also a GPU-optimized version of LibSci, called LibSCi_ACC, which contains a subset of the routines of LibSci. We don't have much experience in the support team with this library though. It can be compared with what Intel is doing with oneAPI MKL which also offers GPU versions of some of the traditional MKL routines.
Another separate component of the scientific and mathematical libraries is FFTW3, Fastest Fourier Transforms in the West, which comes with optimized versions for all CPU architectures supported by recent HPE Cray machines.
Finally, the scientific and math libraries also contain HDF5 and netCDF libraries in sequential and parallel versions.
Cray MPI¶

HPE Cray build their own MPI library with optimisations for their own interconnects. The Cray MPI library is derived from the ANL MPICH 3.4 code base and fully support the ABI (Application Binary Interface) of that application which implies that in principle it should be possible to swap the MPI library of applications build with that ABI with the Cray MPICH library. Or in other words, if you can only get a binary distribution of an application and that application was build against an MPI library compatible with the MPICH 3.4 ABI (which includes Intel MPI) it should be possible to exchange that library for the Cray one to have optimised communication on the Cray Slingshot interconnect.
Cray MPI contains many tweaks specifically for Cray systems. HPE Cray claim improved algorithms for many collectives, an asynchronous progress engine to improve overlap of communications and computations, customizable collective buffering when using MPI-IO, and optimized remote memory access (MPI one-sided communication) which also supports passive remote memory access.
When used in the correct way (some attention is needed when linking applications) it is allo fully GPU aware with currently support for AMD and NVIDIA GPUs.
The MPI library also supports bindings for Fortran 2008.
MPI 3.1 is almost completely supported, with two exceptions. Dynamic process management is not supported (and a problem anyway on systems with batch schedulers), and when using CCE MPI_LONG_DOUBLE and MPI_C_LONG_DOUBLE_COMPLEX are also not supported.
The Cray MPI library does not support the mpirun or mpiexec commands, which is in fact
allowed by the standard which only requires a process starter and suggest mpirun or mpiexec
depending on the version of the standard. Instead the Slurm srun command is used as the
process starter. This actually makes a lot of sense as the MPI application should be mapped
correctly on the allocated resources, and the resource manager is better suited to do so.
Cray MPI on LUMI is layered on top of libfabric, which in turn uses the so-called Cassini provider to interface with the hardware. UCX is not supported on LUMI (but Cray MPI can support it when used on InfiniBand clusters). It also uses a GPU Transfer Library (GTL) for GPU-aware MPI.
Lmod¶

Virtually all clusters use modules to enable the users to configure the environment and select the versions of software they want. There are three different module systems around. One is an old implementation that is hardly evolving anymore but that can still be found on\ a number of clusters. HPE Cray still offers it as an option. Modulefiles are written in TCL, but the tool itself is in C. The more popular tool at the moment is probably Lmod. It is largely compatible with modulefiles for the old tool, but prefers modulefiles written in LUA. It is also supported by the HPE Cray PE and is our choice on LUMI. The final implementation is a full TCL implementation developed in France and also in use on some large systems in Europe.
Fortunately the basic commands are largely similar in those implementations, but what differs is the way to search for modules. We will now only discuss the basic commands, the more advanced ones will be discussed in the next session of this tutorial course.
Modules also play an important role in configuring the HPE Cray PE, but before touching that topic we present the basic commands:
module avail: Lists all modules that can currently be loaded.module list: Lists all modules that are currently loadedmodule load: Command used to load a module. Add the name and version of the module.module unload: Unload a module. Using the name is enough as there can only one version be loaded of a module.module swap: Unload the first module given and then load the second one. In Lmod this is really equivalent to amodule unloadfollowed by amodule load.
Lmod supports a hierarchical module system. Such a module setup distinguishes between installed modules and available modules. The installed modules are all modules that can be loaded in one way or another by the module systems, but loading some of those may require loading other modules first. The available modules are the modules that can be loaded directly without loading any other module. The list of available modules changes all the time based on modules that are already loaded, and if you unload a module that makes other loaded modules unavailable, those will also be deactivated by Lmod. The advantage of a hierarchical module system is that one can support multiple configurations of a module while all configurations can have the same name and version. This is not fully exploited on LUMI, but it is used a lot in the HPE Cray PE. E.g., the MPI libraries for the various compilers on the system all have the same name and version yet make different binaries available depending on the compiler that is being used.
Compiler wrappers¶

The HPE Cray PE compilers are usually used through compiler wrappers.
The wrapper for C is cc, the one for C++ is CC and the one for Fortran is ftn.
The wrapper then calls the selected compiler. Which compiler will be called is determined
by which compiler module is loaded. As shown on the slide
"Development environment on LUMI", on LUMI
the Cray Compiling Environment (module cce), GNU Compiler Collection (module gcc),
the AMD Optimizing Compiler for CPUs (module aocc) and the ROCm LLVM-based compilers
(module amd) are available. On other HPE Cray systems, you may also find the Intel
compilers or on systems with NVIDIA GPUS, the NVIDIA HPC compilers.
The target architectures for CPU and GPU are also selected through modules, so it is better
to not use compiler options such as -march=native. This makes cross compiling also easier.
The wrappers will also automatically link in certain libraries, and make the include files available, depending on which other modules are loaded. In some cases it tries to do so cleverly, like selecting an MPI, OpenMP, hybrid or sequential option depending on whether the MPI module is loaded and/or OpenMP compiler flag is used. This is the case for:
- The MPI libraries. There is no
mpicc,mpiCC,mpif90, etc. on LUMI. The regular compiler wrappers do the job as soon as thecray-mpichmodule is loaded. - LibSci and FFTW are linked automatically if the corresponding modules are loaded. So no need
to look, e.g., for the BLAS or LAPACK libraries: They will be offered to the linker if the
cray-libscimodule is loaded (and it is an example of where the wrappers try to take the right version based not only on compiler, but also on whether MPI is loaded or not and the OpenMP compiler flag). - netCDF and HDF5
It is possible to see which compiler and linker flags the wrappers add through the --craype-verbose
flag.
The wrappers do have some flags of their own, but also accept all flags of the selected compiler and simply pass those to those compilers.
Selecting the version of the CPE¶

The version numbers of the HPE Cray PE are of the form yy.dd, e.g., 22.08 for the version
released in August 2022. There are usually 10 releases per year (basically every month except July
and January), though not all versions are ever offered on LUMI.
There is always a default version assigned by the sysadmins when installing the programming
environment. It is possible to change the default version for loading further modules
by loading one of the versions of the cpe module. E.g., assuming the 22.08 version would be
present on the system, it can be loaded through
module load cpe/22.08
module load twice will fix this:
module load cpe/22.08
module load cpe/22.08
module load of cpe when one is already loaded, as it then first unloads the already
loaded cpe module). The warning can be ignored, but keep in mind that what it says is true,
it cannot restore the environment you found on LUMI at login.
The cpe module is also not needed when using the LUMI software stacks, but more about that
later.
The target modules¶

The target modules are used to select the CPU and GPU optimization targets and to select the network communication layer.
On LUMI there are three CPU target modules that are relevant:
craype-x86-romeselects the Zen2 CPU family code named Rome. These CPUs are used on the login nodes and the nodes of the data analytics and visualisation partition of LUMI. However, as Zen3 is a superset of Zen2, software compiled to this target should run everywhere, but may not exploit the full potential of the LUMI-C and LUMI-G nodes (though the performance loss is likely minor).craype-x86-milanis the target module for the Zen3 CPUs code named Milan that are used on the CPU-only compute nodes of LUMI (the LUMI-C partition).craype-x86-trentois the target module for the Zen3 CPUs code named Trento that are used on the GPU compute nodes of LUMI (the LUMI-G partition).
Two GPU target modules are relevant for LUMI:
craype-accel-host: Will tell some compilers to compile offload code for the host instead.craype-accel-gfx90a: Compile offload code for the MI200 series GPUs that are used on LUMI-G.
Two network target modules are relevant for LUMI:
craype-network-ofiselects the libfabric communication layer which is needed for Slingshot 11.craype-network-noneomits all network specific libraries.
The compiler wrappers also have corresponding compiler flags that can be used to overwrite these
settings: -target-cpu, -target-accel and -target-network.
PrgEnv and compiler modules¶

In the HPE Cray PE, the PrgEnv-* modules are usually used to load a specific variant of the
programming environment. These modules will load the compiler wrapper (craype), compiler,
MPI and LibSci module and may load some other modules also.
The following table gives an overview of the available PrgEnv-* modules and the compilers they
activate:
| PrgEnv | Description | Compiler module | Compilers |
|---|---|---|---|
| PrgEnv-cray | Cray Compiling Environment | cce |
craycc, crayCC, crayftn |
| PrgEnv-gnu | GNU Compiler Collection | gcc |
gcc, g++, gfortran |
| PrgEnv-aocc | AMD Optimizing Compilers (CPU only) |
aocc |
clang, clang++, flang |
| PrgEnv-amd | AMD ROCm LLVM compilers (GPU support) |
amd |
amdclang, amdclang++, amdflang |
There is also a second module that offers the AMD ROCm environment, rocm. That module
has to be used with PrgEnv-cray and PrgEnv-gnu to enable MPI-aware GPU,
hipcc with the GNU compilers or GPU support with the Cray compilers.
Getting help¶
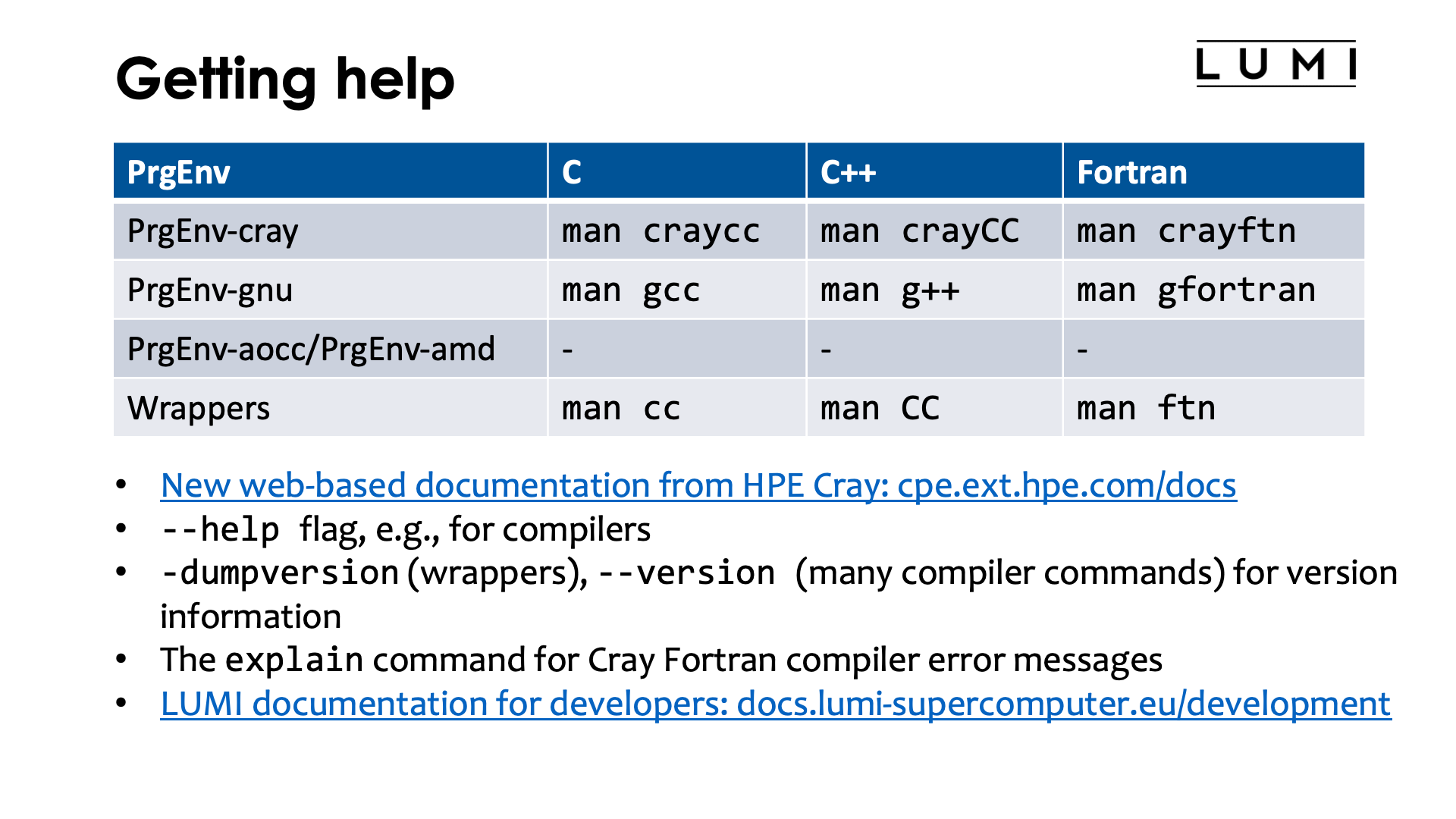
Help on the HPE Cray Programming Environment is offered mostly through manual pages and compiler flags. Online help is limited and difficult to locate.
For the compilers and compiler wrappers, the following man pages are relevant:
| PrgEnv | C | C++ | Fortran |
|---|---|---|---|
| PrgEnv-cray | man craycc |
man crayCC |
man crayftn |
| PrgEnv-gnu | man gcc |
man g++ |
man gfortran |
| PrgEnv-aocc/PrgEnv-amd | - | - | - |
| Compiler wrappers | man cc |
man CC |
man ftn |
Recently, HPE Cray have also created a web version of some of the CPE documentation.
Some compilers also support the --help flag, e.g., amdclang --help. For the wrappers,
the switch -help should be used instead as the double dash version is passed to the
compiler.
The wrappers also support the -dumpversion flag to show the version of the underlying compiler.
Many other commands, including the actual compilers, use --version to show the version.
For Cray Fortran compiler error messages, the explain command is also helpful. E.g.,
$ ftn
ftn-2107 ftn: ERROR in command line
No valid filenames are specified on the command line.
$ explain ftn-2107
Error : No valid filenames are specified on the command line.
At least one file name must appear on the command line, with any command-line
options. Verify that a file name was specified, and also check for an
erroneous command-line option which may cause the file name to appear to be
an argument to that option.
On older Cray systems this used to be a very useful command with more compilers but as
HPE Cray is using more and more open source components instead there are fewer commands
that give additional documentation via the explain command.
Lastly, there is also a lot of information in the "Developing" section of the LUMI documentation.
Google, ChatGPT and LUMI¶

When looking for information on the HPE Cray Programming Environment using search engines such as Google, you'll be disappointed how few results show up. HPE doesn't put much information on the internet, and the environment so far was mostly used on Cray systems of which there are not that many.
The same holds for ChatGPT. In fact, much of the training of the current version of ChatGPT was done with data of two or so years ago and there is not that much suitable training data available on the internet either.
The HPE Cray environment has a command line alternative to search engines though: the man -K command
that searches for a term in the manual pages. It is often useful to better understand some error messages.
E.g., sometimes Cray MPICH will suggest you to set some environment variable to work around some problem.
You may remember that man intro_mpi gives a lot of information about Cray MPICH, but if you don't and,
e.g., the error message suggests you to set FI_CXI_RX_MATCH_MODE to either software or hybrid, one way
to find out where you can get more information about this environment variable is
man -K FI_CXI_RX_MATCH_MODE
Other modules¶

Other modules that are relevant even to users who do not do development:
- MPI:
cray-mpich. - LibSci:
cray-libsci - Cray FFTW3 library:
cray-fftw - HDF5:
cray-hdf5: Serial HDF5 I/O librarycray-hdf5-parallel: Parallel HDF5 I/O library
- NetCDF:
cray-netcdfcray-netcdf-hdf5parallelcray-parallel-netcdf
- Python:
cray-python, already contains a selection of packages that interface with other libraries of the HPE Cray PE, including mpi4py, NumPy, SciPy and pandas. - R:
cray-R
The HPE Cray PE also offers other modules for debugging, profiling, performance analysis, etc. that are not covered in this short version of the LUMI course. Many more are covered in the 4-day courses for developers that we organise several times per year with the help of HPE and AMD.
Warning 1: You do not always get what you expect...¶

The HPE Cray PE packs a surprise in terms of the libraries it uses, certainly for users who come from an environment where the software is managed through EasyBuild, but also for most other users.
The PE does not use the versions of many libraries determined by the loaded modules at runtime
but instead uses default versions of libraries (which are actually in /opt/cray/pe/lib64 on the system)
which correspond to the version of the programming environment that is set as the default when installed.
This is very much the behaviour of Linux applications also that pick standard libraries in a few standard
directories and it enables many programs build with the HPE Cray PE to run without reconstructing the
environment and in some cases to mix programs compiled with different compilers with ease (with the
emphasis on some as there may still be library conflicts between other libraries when not using the
so-called rpath linking). This does have an annoying side effect though: If the default PE on the system
changes, all applications will use different libraries and hence the behaviour of your application may
change.
Luckily there are some solutions to this problem.
By default the Cray PE uses dynamic linking, and does not use rpath linking, which is a form of dynamic
linking where the search path for the libraries is stored in each executable separately. On Linux, the
search path for libraries is set through the environment variable LD_LIBRARY_PATH. Those Cray PE modules
that have their libraries also in the default location, add the directories that contain the actual version
of the libraries corresponding to the version of the module to the PATH-style environment variable
CRAY_LD_LIBRARY_PATH. Hence all one needs to do is to ensure that those directories are put in
LD_LIBRARY_PATH which is searched before the default location:
export LD_LIBRARY_PATH=$CRAY_LD_LIBRARY_PATH:$LD_LIBRARY_PATH
Small demo of adapting LD_LIBRARY_PATH:
An example that can only be fully understood after the section on the LUMI software stacks:
$ module load LUMI/22.08
$ module load lumi-CPEtools/1.0-cpeGNU-22.08
$ ldd $EBROOTLUMIMINCPETOOLS/bin/mpi_check
linux-vdso.so.1 (0x00007f420cd55000)
libdl.so.2 => /lib64/libdl.so.2 (0x00007f420c929000)
libmpi_gnu_91.so.12 => /opt/cray/pe/lib64/libmpi_gnu_91.so.12 (0x00007f4209da4000)
...
$ export LD_LIBRARY_PATH=$CRAY_LD_LIBRARY_PATH:$LD_LIBRARY_PATH
$ ldd $EBROOTLUMIMINCPETOOLS/bin/mpi_check
linux-vdso.so.1 (0x00007fb38c1e0000)
libdl.so.2 => /lib64/libdl.so.2 (0x00007fb38bdb4000)
libmpi_gnu_91.so.12 => /opt/cray/pe/mpich/8.1.18/ofi/gnu/9.1/lib/libmpi_gnu_91.so.12 (0x00007fb389198000)
...
ldd command shows which libraries are used by an executable. Only a part of the very long
output is shown in the above example. But we can already see that in the first case, the library
libmpi_gnu_91.so.12 is taken from opt/cray/pe/lib64 which is the directory with the default
versions, while in the second case it is taken from /opt/cray/pe/mpich/8.1.18/ofi/gnu/9.1/lib/
which clearly is for a specific version of cray-mpich.
We do provide an experimental module lumi-CrayPath
that tries to fix LD_LIBRARY_PATH in a way that unloading
the module fixes LD_LIBRARY_PATH again to the state before adding CRAY_LD_LIBRARY_PATH and that
reloading the module adapts LD_LIBRARY_PATH to the current value of CRAY_LD_LIBRARY_PATH. Loading that
module after loading all other modules should fix this issue for most if not all software.
The second solution would be to use rpath-linking for the Cray PE libraries, which can be done by setting
the CRAY_ADD_RPATHenvironment variable:
export CRAY_ADD_RPATH=yes
Warning 2: Order matters¶

Lmod is a hierarchical module scheme and this is exploited by the HPE Cray PE. Not all modules are available right away and some only become available after loading other modules. E.g.,
cray-fftwonly becomes available when a processor target module is loadedcray-mpichrequires both the network target modulecraype-network-ofiand a compiler module to be loadedcray-hdf5requires a compiler module to be loaded andcray-netcdfin turn requirescray-hdf5
but there are many more examples in the programming environment.
In the next section of the course we will see how unavailable modules can still be found
with module spider. That command can also tell which other modules should be loaded
before a module can be loaded, but unfortunately due to the sometimes non-standard way
the HPE Cray PE uses Lmod that information is not always complete for the PE, which is also
why we didn't demonstrate it here.