LUMI AI Guide¶
Presenters: Gregor Decristoforo (LUST)
Additional materials¶
Q&A from the HedgeDoc document¶
-
I use the PyTorch module, and create a virtual environment on top of that for additional packages. The number of files in my virtual environment is around ~1500 files. Is this a large number causing a slow execution of my code or strain on the Lustre file system? If it does affect the speed, is it only limited to the module importing phase? Once training begins, should we expect normal performance?
-
It depends. Also how is the training dataset organized? is that a single file or many?
-
The last point on this page describes how you can turn the virtual environment into a SquashFS file and mount that to the container.
-
-
When I create an interactive session for VSCode through the web browser, I load the
pytorch/2.4module. However, when I try to select the Python interpreter in the VSCode session, I encounter "invalid Python interpreter" error.- One can use
module load Local-CSCinstead ofmodule use /appl/local/csc/modulefiles. The documentation still isn't updated accordingly unfortunately. I quickly tested the VScode web app with adding Local-CSC pytorch/2.4 to the modules field and it detects the right python version with torch installed.
- One can use
-
I'm in the optimization stage of my project and found that my
rocblas _<T>gemmroutines are delivering a poor performance on a single Die ofMI250Xcompared to how the same code performs on aA100NVidia GPU. To my knowledge, LUMI's GPUs should surpass NVidia's by at least a factor of2x. Specially inFP64operations. A close examination using the rocblas-bench with square matrix multiplication, has revealed an inconsistent behaviour on the GEMM routines. For example,rocblas_dgemmroutine: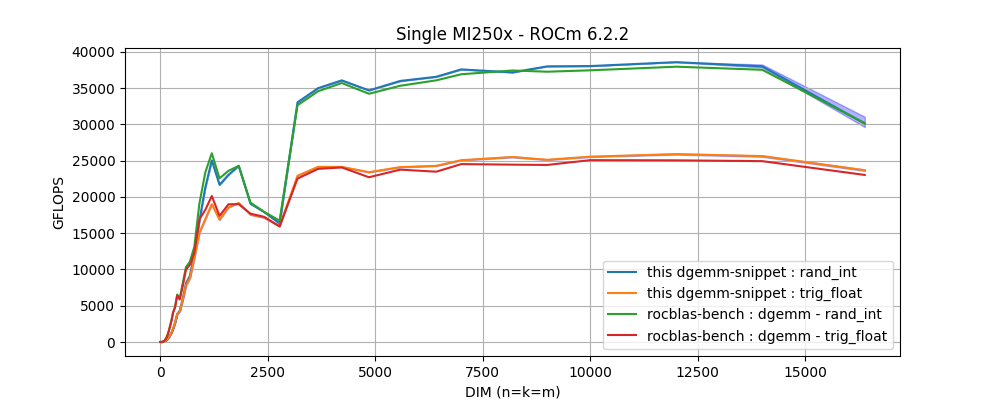 In this figure, two performance behaviors are found: the highest performance is obtained with arrays filled with integer values randomly
picked from a limited range, and a lower performance when data is initialized with values generated from trigonometric functions.
In other words, a performance degradation is observed on
In this figure, two performance behaviors are found: the highest performance is obtained with arrays filled with integer values randomly
picked from a limited range, and a lower performance when data is initialized with values generated from trigonometric functions.
In other words, a performance degradation is observed on dgemmwith the only difference being the arrays initialization.Q1: Is this the expected behavior? and if not, how can we get the maximum performance with arbitrary input data?
- I have reported to
LUMI supportand theROCm/Tensileproject ongithub(see issue #2118). - In rocblas issue #1486, it has been pointed to me that the most likely explanation is due to a Dynamic Power Management. But, my lastest discussion with Bert Jorissen indicated me that, for these 5 mins test, no reduction of the device frequency is experienced.
Q2: Is there a way to verify whether DPM is actually reducing our performance when arbitrary data is used in the benchmark?
-
These questions are outside of what LUST can do. We're L1-L2 and not L3. Discuss directly with AMD who is usually present in the coffee break, in a break-out room. And the hackathons serve to help with optimizing code.
-
But your idea about the speed of an MI250X die is wrong. There is more than peak performance. There is also the cost to start up a kernel, and the memory bandwidth isn't higher than on A100. So in practice we're happy if a single die can keep up with an A100.
-
And if you really want to understand what's happening, you should not speculate about dynamic power management (which shouldn't have a huge influence as we're talking about relatively small variations in clock speed), but should use proper profiles to see where the code gets stuck. The performance degradation may come from a totally different source than you expect...
- I have reported to
-
I have difficulties in installing conda environment (flash-attention 2) for training LLMs. I wonder if there is a hand-on video about the installation process. The LUMI environment is different to the system in CSC.
- How did you try to install the conda environment? using conda directly or one of our tools?
I am trying to use the Container provided by LUMI, but instructions are difficult to follow for me. I would like to install my conda environment inside the container. Things may become simple after trying the github AI guides.
-
If you have a container that you want to extend maybe try using cotainr or lumi-container-wrapper to extend it.
-
The containers come with a conda environment inside which you have to activate.
-
Check the example in the AI guide: https://github.com/Lumi-supercomputer/LUMI-AI-Guide/tree/main/2-setting-up-environment
I get stuck with the EasyBuild version of PyTorch (https://lumi-supercomputer.github.io/LUMI-EasyBuild-docs/p/PyTorch/). I do not know how to install PyTorch using EasyBuild. But it seems not necessary for using pytorch. I use the other option
Directly, with you taking care of all bindings and all necessary environment variablesand it looks very convenient. Now I get access to the container and there seems to be flash-attn2.- The PyTorch EasyBuild recipes don't install PyTorch but a wrapper around the container. We have plenty of course materials that tell you how to use it, so please check out the software stack talk from our latest course (and we even have some recorded demos in the materials of that course).
-
I am getting an error related to the missing OS library called libgthread. It's related to the opencv-python library (using headless version didn't help) and required to have on a system level. Users can't add this library because of permission restrictions. I also discussed this with Triton support at my university, they told me that you should install this library. Using different container version didn't help (I followed guideline here).
-
Have you tried an unpriviliged
prootbuild? That way you can extend a prebuild container with system libraries. Check out this section of our training course. -
Please take our trainings as we explain why we cannot install everything on the system as we are (a) a large and scalable HPC infrastructure, not a workstation and (b) have to serve multiple users with conflicting expectations. Such things should be done in containers, using the "unprivileged proot build" process, and we have tutorials and demos about it in our latest training materials. Have a look at the software stack talk from our latest course.
-
-
Is there imagenet-1k dataset on LUMI machine? I know that there is mini-dataset, but I wasn't able to find imagenet-1k full dataset with 1000 labels.
-
We use the mini-dataset for the AI guide. The whole dataset with 1000 labels is not publicly available on LUMI but you can download it yourself here.
-
Storing datasets and converting them to proper formats for use on LUMI is the responsibility of the user. We have no central common data store as this is impossible to manage.
-